Scraping a site
Open the site that you want to scrape.
Create Sitemap
The first thing you need to do when creating a sitemap is specifying the
start url. This is the url from which the scraping will start. You can also
specify multiple start urls if the scraping should start from multiple places.
For example if you want to scrape multiple search results then you could create
a separate start url for each search result. Additional URL input fields can be added
by pressing + next to the URL input. Once the sitemap is created, start URL
tab can be found by selecting Edit metadata in Sitemap sitemap_name
dropdown.

Specify multiple urls with ranges
In cases where a site uses numbering in pages URLs it is much simpler to create
a range start url than creating Link selectors that would navigate the site.
To specify a range url replace the numeric part of start url with a range
definition - [1-100]. If the site uses zero padding in urls then add zero
padding to the range definition - [001-100]. If you want to skip some urls
then you can also specify incremental like this [0-100:10].
Use range url like this https://example.com/page/[1-3] for links like these:
https://example.com/page/1https://example.com/page/2https://example.com/page/3
Use range url with zero padding like this https://example.com/page/[001-100]
for links like these:
https://example.com/page/001https://example.com/page/002https://example.com/page/003
Use range url with increment like this https://example.com/page/[0-100:10] for
links like these:
https://example.com/page/0https://example.com/page/10https://example.com/page/20
Create selectors
After you have created a sitemap you can begin to add, modify, and navigate selectors in the Selectors panel.
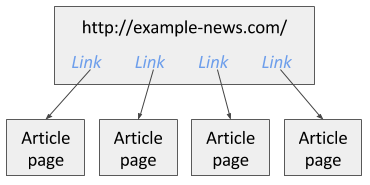
The selectors are added in a tree type structure. The web scraper will execute the selectors in the order how they are organized in the tree structure. For example there is a news site and you want to scrape all article links which are available on the first page. In image 1 you can see this example site.
To scrape this site you can create a Link selector which will extract all article links in the first page. Then as a child selector you can add a Text selector that will extract articles from the article pages that the Link selector found links to. Image below illustrates how the sitemap should be built for the news site.
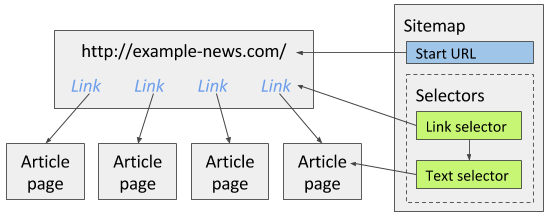
Note that when creating selectors, Element preview and Data preview features ensure that you have selected the correct elements with the correct data.
More information about selector tree building is available in selector documentation. You should at least read about these core selectors:
Scrape the site
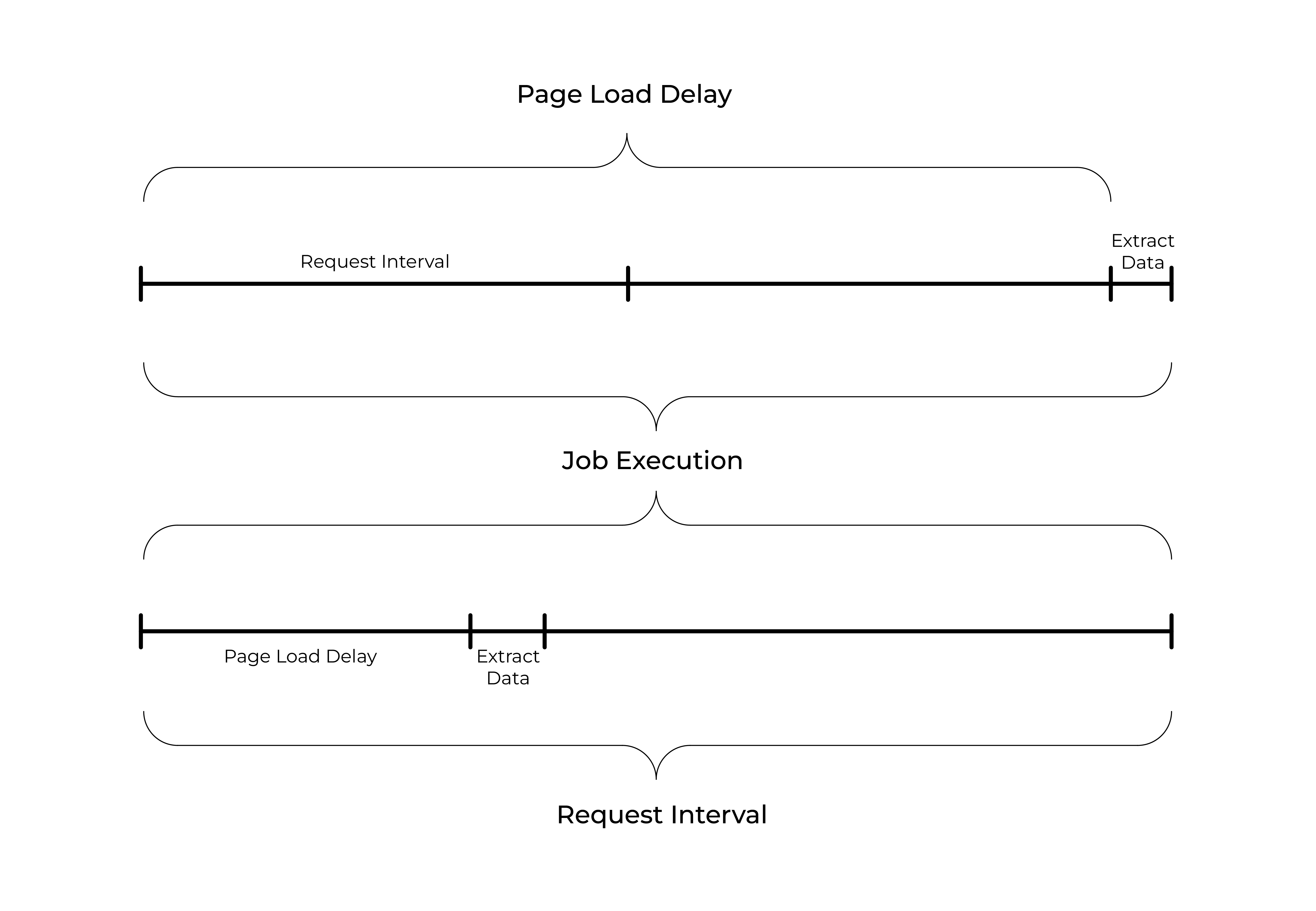
After you have created selectors for the sitemap you can start scraping. Open Scrape panel and start scraping. Optionally, you can change request interval and page load delay. A new popup window will open in which the scraper will load pages and extract data from them. After the scraping is done the popup window will close and you will be notified with a popup message. You can view the scraped data by opening Browse panel and export it by opening the Export data as CSV panel.

Request Interval - the minimal amount of time between the requests.
Page Load Delay - the amount of time the scraper will wait before starting to execute selectors once a page has rendered.