Link selector
Link selector is used for link selection and website navigation. If you use Link selector without any child selectors then it will extract the link and the href attribute of the link. If you add child selectors to Link selector then these child selectors will be used in the page that this link was leading to. If you are selecting multiple links then check multiple property.
Note! Check that the link in the URL bar changes after clicking on an item. If it does not, then, most likely, the site is using AJAX for data loading. Instead of using a link selector, you should use Pagination selector.
The Link selector can extract links from 5 types of sources:
- Link - reads the
hrefattribute of an element. E.g.<a href="https://example.com">; - Text - reads the text content of an element. E.g.
<span>https://example.com</span>; - Attribute - reads the attributes of an element and finds the link. E.g.
<a data-link="https://example.com">; - Scripted link in attribute - reads the scripted link in an attribute. E.g.
<a onclick="window.location='https://example.com'">; - Link from any script - reads link from a script. E.g.
<a(window.location=, window.open)>;
All Link Selector types except for 'Link from any script' only allow selecting elements using the point-and-click interface although other elements can be selected by manually entering the CSS selector value as a selector.
The 'Link from any script' type allows any element to be selected using the point-and-click interface.
Configuration options
- selector - CSS selector for the link element from which the link for navigation will be extracted.
- multiple - multiple records are being extracted. Usually should be checked.
- link type - the source of the link. See above for more information.
Use cases
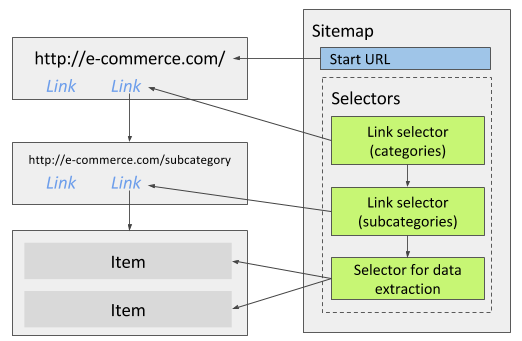
Navigate through multiple levels of navigation
For example an e-commerce site has multi level navigation -
categories -> subcategories. To scrape data from all categories and
subcategories you can create two Link selectors. One selector would select
category links and the other selector would select subcategory links that are
available in the category pages. The subcategory Link selector should be made
as a child of the category Link selector. The selectors for data extraction
from subcategory pages should be made as a child selectors to the subcategory
selector.