Web Scraper Cloud
Web Scraper Cloud is a premium service that enriches Web Scraper with automation features, improves scraped data consistency, is scalable and allows to monitor scraping jobs. It uses sitemaps that are built by using Web Scraper browser extension to run scraping jobs.
Features
Proxy
Proxy is used in order to prevent scraper of being blocked by the target site or to access the site from a non-restricted location. By the default, the proxy uses IP addresses located in the US. Other location IP addresses can be requested by contacting support. Additional residential proxy locations can be seen by expanding the proxy dropdown.
When the proxy is enabled, the scraper will rotate IP addresses every 5 minutes. If the page fails to load with proxy enabled, scraper changes the IP address and retries to scrape the page.
Other features
Page credits
A page credit represents a single page loaded by the Web Scraper Cloud. For example, if the scraper has to navigate through 100 pages, then 100 page credits will be subtracted from your account. If you are extracting 100 records from a single page, only one page credit will be charged.
Page credits are not subtracted when re-scraping empty or failed pages.
Parallel tasks
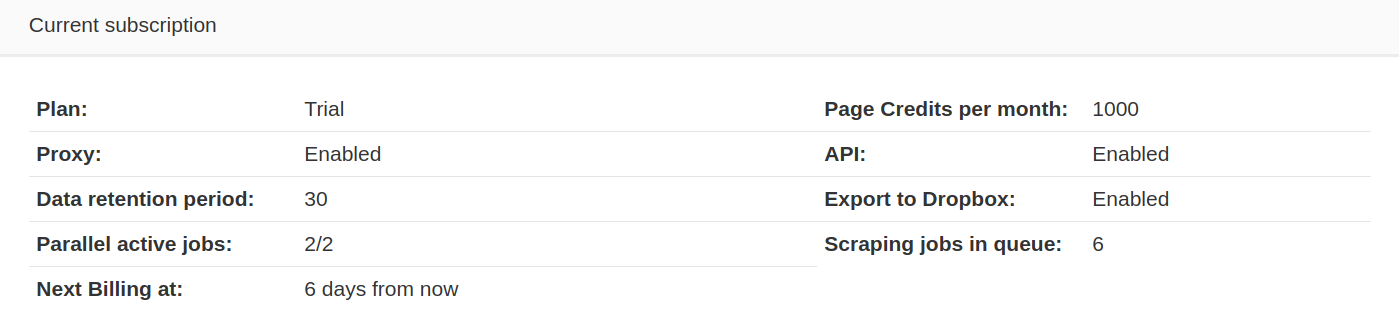
A parallel task count represents how many scraping jobs can run at once. If all parallel tasks are in use and new scraping job is started, it will be scheduled and added to a queue whilst waiting for a task to free up. Scraping jobs can be manually stopped and continued to free up a parallel task or change the order in which the scraping jobs will be executed. Parallel active scraping job count and scraping job count in queue can be found in Subscription manager page.
Drivers
Web Scraper Cloud has 2 types of drivers to run scraping jobs on:
Fulldriver - loads the page the same way as Web Scraper browser extension. All assets are loaded and JavaScript is executed before data extraction starts;Fastdriver - doesn't execute JavaScript in the page. Data is extracted from raw HTML. The page loads faster than withFulldriver or Web Scraper browser extension.
Progress monitoring
In the scraping job table views you can track the progress of each scraping job:
- Scraped pages - scraped page count and total scheduled page count.
- Scraped record count - data rows extracted.
- Failed pages - pages that loaded with 4xx or 5xx response code or didn't load at all.
- Empty pages - pages that loaded successfully but selectors didn't extract any data.
- No value pages - pages where the scraper found matching elements but extracted no actual values within the final dataset.
Our built-in fail-over system automatically re-scrapes any empty and failed pages. If empty and/or failed pages are still present after the scraping job has finished, it can be continued manually in scraping job list view.
Scraping job inspection and troubleshooting
When troubleshooting a scraping job, a list of empty and failed pages with screenshots (only for Full driver) can be
found by navigating to scraping job Inspect page from the scraping job list
view. Details tab in scraping job Inspect page contains scraping job
configuration with sitemap and scraping job IDs and scraping duration. Scraping
duration represents time the scraper is actually scraping the site without any
status changes and queue times.
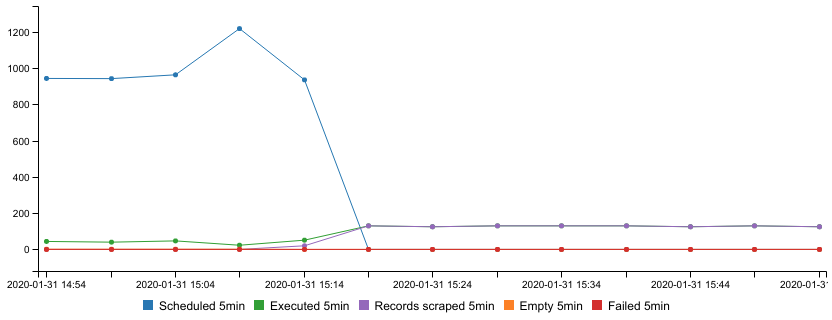
Additionally, a performance graph is available while the scraping job is running. Data in this graph is kept for 7 days. It can be used to monitor the activity of the scraping job and to estimate the time necessary until the full completion. The graph shows these values in 5-minute intervals:
- Scheduled pages;
- Executed pages;
- Records scraped;
- Empty pages;
-
Failed pages.
Limits
- Start URL limit - 20'000.
- Selector limit - 100.
- Data extraction execution time from a single URL - 10 minutes. Can be reached by using scroll down selector on infinite scroll down or element click selector. If the timeout is reached, no data will be scraped from that page.
Difference between scraping on Web Scraper Cloud and Web Scraper browser extension
| Web Scraper Cloud | Web Scraper Browser Extension |
|---|---|
| Consistent site accessibility while scraping. Automatic failover, IP address rotation, and data extraction retry mechanisms decrease the chance of the scraper access getting blocked. | Limited access. Only sites that you can access via your browser can be scraped. For small data extraction volumes, this is good enough. |
| Scraped data is stored in cloud storage for all scraping jobs within the data retention period. | Only data from the latest scraping job is stored in the browser's local storage. |
| Images are not loaded while scraping. This decreases page load time as well as transferred data for custom proxy users. | Images are loaded while scraping. |
| URLs are traversed in pseudo-random order. This ensures the most recent data is being scraped when crawling larger sites. | URLs are traversed in last in, first out order based on how they were discovered. This will discover the initial records sooner but won't decrease the total time required to scrape the site. |