Text selector
Text selector is used for text selection. The text selector will extract text
from the selected element and from all its child elements. HTML will be
stripped and only text will be returned. Selector will ignore text within
<script> and <style> tags. New line <br> tags will be replaced with
newline characters. You can additionally apply a regular expression to
resulting data.
Configuration options
- selector - CSS selector for the element from which data will be extracted.
- multiple type - multiple records are being extracted. Usually should not be checked. If you want to use multiple text selectors within one page with multiple checked then you might actually need
- column count - the number of columns returned when multiple type is set to
Multiple Records in Multiple ColumnsElement selector.
Use cases
Extract one record per page with multiple text selectors
For example you are scraping news site that has one article per page. The page might contain the article, its title, date published and the author. A Link selector can navigate the scraper to each of these article pages. Multiple text selectors can extract the title, date, author and article. Multiple option should be left unchecked for text selectors because each page is extracting only one record.
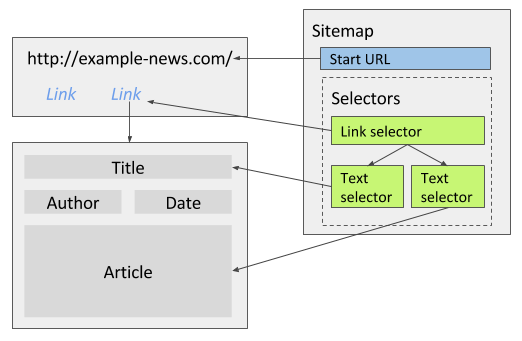
Extract multiple items with multiple text selectors per page
E-commerce sites usually have multiple items per page. If you want to scrape these items you will need an Element selector that selects item wrapper elements and multiple text selectors that select data within each item wrapper element.
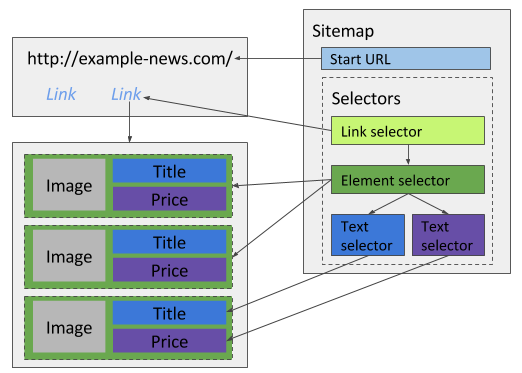
Extract multiple text records per page
For example you want to extract comments for an article. There are multiple comments in a single page and you only need the comment text (If you would need other comment attributes then see the example above). You can use Text selector to extract these comments. The preferred Text selectors multiple type should be selected to enable extracting multiple elements
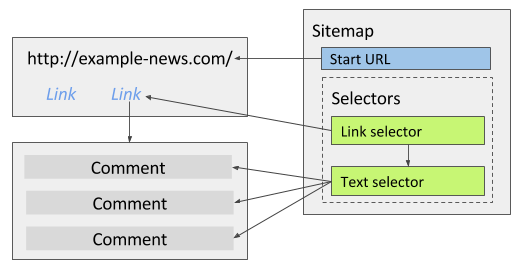
Multiple Type
A specific selector can find multiple items on a single site. To handle this a Multiple Type
is available when creating the selector. The selected type affects
how data is returned
First Record Only- returns only the first record extracted. Use when only one record expectedMultiple Records in Multiple Columns- returns multiple records split into up toColumn Countcolumns. Enables and Requires fillingColumn count(defaults to 5)Multiple Records in One Column- returns all extracted records in a single column joined by 2 newlines (replaces mulitple newlines in extracted text with one)