Sitemap.xml link selector
Sitemap.xml link selector can be used similarly as Link selector to get to target pages (for example product pages).
By using this selector, the whole site can be traversed without setting up selectors for pagination or other site navigation.
The Sitemap.xml link selector extracts URLs from sitemap.xml files which websites publish so that search engine crawlers can navigate the sites easier.
In most cases, they contain all of the sites relevant page URLs.
Web Scraper supports standard sitemap.xml format.
The sitemap.xml file can also be compressed (sitemap.xml.gz).
If a sitemap.xml contains URLs to other sitemap.xml files, the selector will work recursively to find all URLs in sub sitemap.xml files.
Note! Web Scraper has download size limit. If multiple sitemap.xml URLs are used, scraping job might fail due to exceeding the limit. To work around this, try splitting the sitemap into multiple sitemaps, where each sitemap has only one sitemap.xml.
Note! Sites that have sitemap.xml files are sometimes quite large.
We recommend using Web Scraper Cloud for large volume scraping.
Configuration options
- sitemap.xml urls - list of URLs of the sites
sitemap.xmlfiles. Multiple URLs can be added. By clicking on "Add from robots.txt" Web Scraper will automatically add allsitemap.xmlURLs that can be found in siteshttps://example.com/robots.txtfile. If no URLs are found, it is worth checkinghttps://example.com/sitemap.xmlURL which might contain asitemap.xmlfile that isn't listed in therobots.txtfile. - found URL RegEx (optional) - regular expression to match a substring from the URLs. If set, only URLs from
sitemap.xmlthat match RegEx will be scraped. - minimum priority (optional) - minimum priority of URLs to be scraped.
Inspect the
sitemap.xmlfile to decide if this value should be filled.
Use cases
Sitemap.xml files are usually used for sites that want to be indexed by search engines, sitemaps can be found for most:
- e-commerce sites;
- travel sites;
- news sites;
- yellow pages.
Best way to scrape the whole site is by using Sitemap.xml link selector. It removes the necessity of dealing with pagination, categories and search forms/queries. Some sites don't display category tree(breadcrumbs) if the page is opened directly. In these cases site has to be traversed through category pages to scrape the category tree.
Making sure that only specific pages are scraped
As in most cases, sitemap.xml contains all pages of the site, it is possible to limit the scraper so it scrapes only
the pages that contain the required data. For example, e-commerce sites sitemap.xml will contain of product pages,
category pages and contact/about/etc. pages. To limit the scraper, so that it scrapes only product pages, one or more methods
can be used:
- Using RegEx - if all product URLs contain a specific string that other type pages don't contain, then this string can
be set in RegEx field and the scraper will traverse only pages that match it. For example,
/product/. This will prevent the scraper from traversing and scraping unnecessary pages. - Setting priority - some sites prioritize specific page types over the others. If that is the case, setting priority will improve scraped page precision.
-
Using wrapper element selector - if none of the previously mentioned methods are possible, an element wrapper selector can be set up. This method works for all sites and doesn't return empty records in the result file if invalid or unnecessary page is traversed. To set up the element wrapper selector, follow these steps:
- Open a few pages that needs to be scraped.
- Find an element that can be found only in these type of pages, for example a product title
h1.product-title. - Create an element selector and set it as a child selector for Sitemap.xml link selector.
- Set element selector to
multipleand set its selector to (for example)body:has(h1.product-title). - Select rest of the selectors as child selectors for this element selector.
The key part of this method is that a unique element has to be found and included in
body:has(unique_selector)selector. If the data from meta tags has to be scraped,htmltag can be used instead ofbodytag. Scraper will extract data only from the pages that have this unique element.
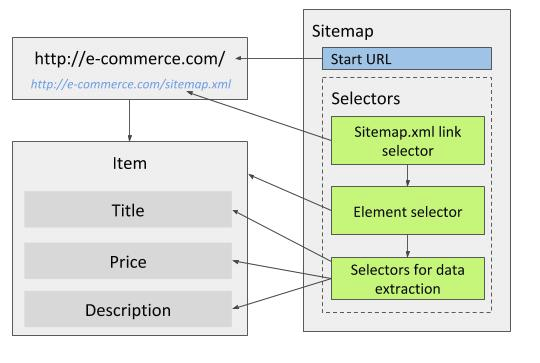
When using Sitemap.xml selector, set the main page of the site as a start URL.