Image export
Web Scraper Cloud supports automated image export to Amazon S3, Google Cloud Storage, and Azure Blob Storage. This feature is available exclusively for Scale plan users. Image downloading is performed during the execution of the scraping job. As pages are processed, associated images are downloaded in parallel with data extraction.
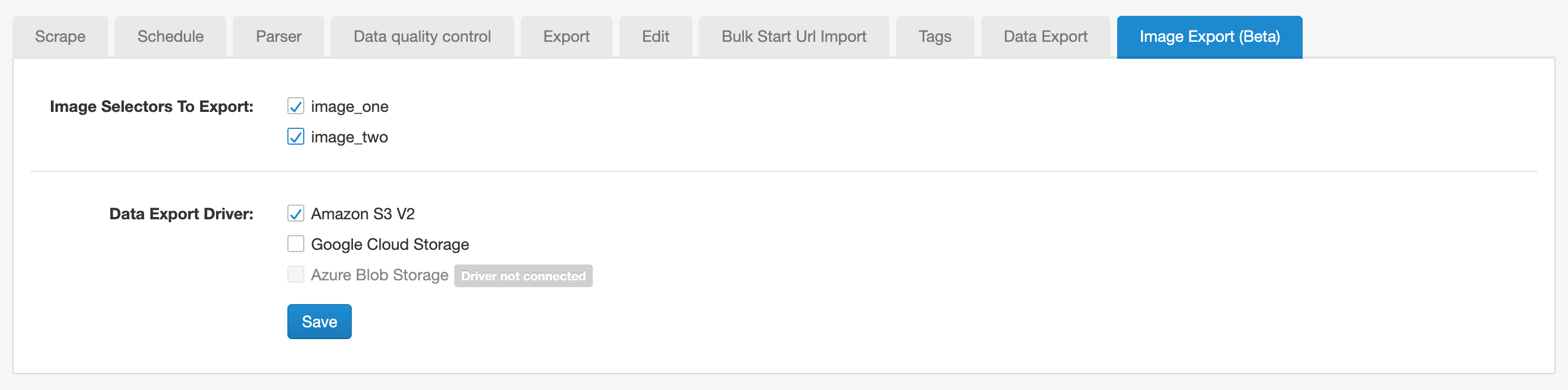
Image export configuration
The image export tab will be visible when the sitemap contains at least one Image selector.
Exported image location
Images are exported to the same path as the data export, within an images subfolder. For example, if data is exported to bucket/web-scraper/my-sitemap in S3, images will be exported to bucket/web-scraper/my-sitemap/images.
Image columns
Each Image selector creates a separate column in the exported data. The column name follows the format {image_selector_id}_stored_filename. File names are generated using the SHA-256 hash of the image URL.

Image column structure based on selector configuration
Example image selector ID: product_image
- First record only -
product_image, product_image_stored_filename - Multiple records in multiple columns -
product_image_1, product_image_1_stored_filename, product_image_2, product_image_2_stored_filename, ... - Multiple records in one column -
product_image, product_image_stored_filename(file names separated by newlines)